kubevirt以容器方式运行虚拟机
容器 & 虚拟机
随着Docker和Kubernetes生态圈的发展,云计算领域对容器的兴趣达到了狂热的程度。
容器技术为应用程序提供了隔离的运行空间,每个容器内都包含一个独享的完整用户环境空间,
容器内的变动不会影响其他容器的运行环境。因为容器之间共享同一个系统内核,当同一个库被多个容器使用时,
内存的使用效率会得到提升。基于物理主机操作系统内核的,那就意味着对于不同内核或者操作系统需求的应用是不可能部署在一起的。
虚拟化技术则是提供了一个完整的虚拟机,为用户提供了不依赖于宿主机内核的运行环境。 对于从物理服务器过渡到虚拟服务器是一个很自然的过程,从用户使用上并没有什么区别。 容器与虚拟机当前看来并不是一个非此即彼的关系,至于采用那种方式去运行应用需要根据具体需求去决定。 在这里笔者并不讨论这个问题,且笔者仅是容器服务的入门玩家,内容若有不准确之处还望斧正。
kubernetes提供了较灵活的容器调度和管理能力,那么虚拟机能否像容器一样被k8s管理调度,
充分利用k8s的故障发现,滚动升级等管理机制呢。
在Linux操作系统中虚拟机本质上就是一个操作系统进程应该是可以运行在容器内部的。
目前Redhat开源的kubevirt和Mirantis开源的virtlet都提供了以容器方式运行虚拟机的方案,
至于两者之间的区别,可以看下这篇Mirantis的
blog。
本文将详细介绍kubevirt项目如何实现运行容器化的虚拟机。
什么是kubevirt
kubevirt是Redhat开源的以容器方式运行虚拟机的项目,以k8s add-on方式,利用k8s CRD为增加资源类型VirtualMachineInstance(VMI),
使用容器的image registry去创建虚拟机并提供VM生命周期管理。
CRD的方式是的kubevirt对虚拟机的管理不用局限于pod管理接口,但是也无法使用pod的RS DS Deployment等管理能力,也意味着
kubevirt如果想要利用pod管理能力,要自主去实现,目前kubevirt实现了类似RS的功能。
kubevirt目前支持的runtime是docker和runv,本文中实践使用的是docker。
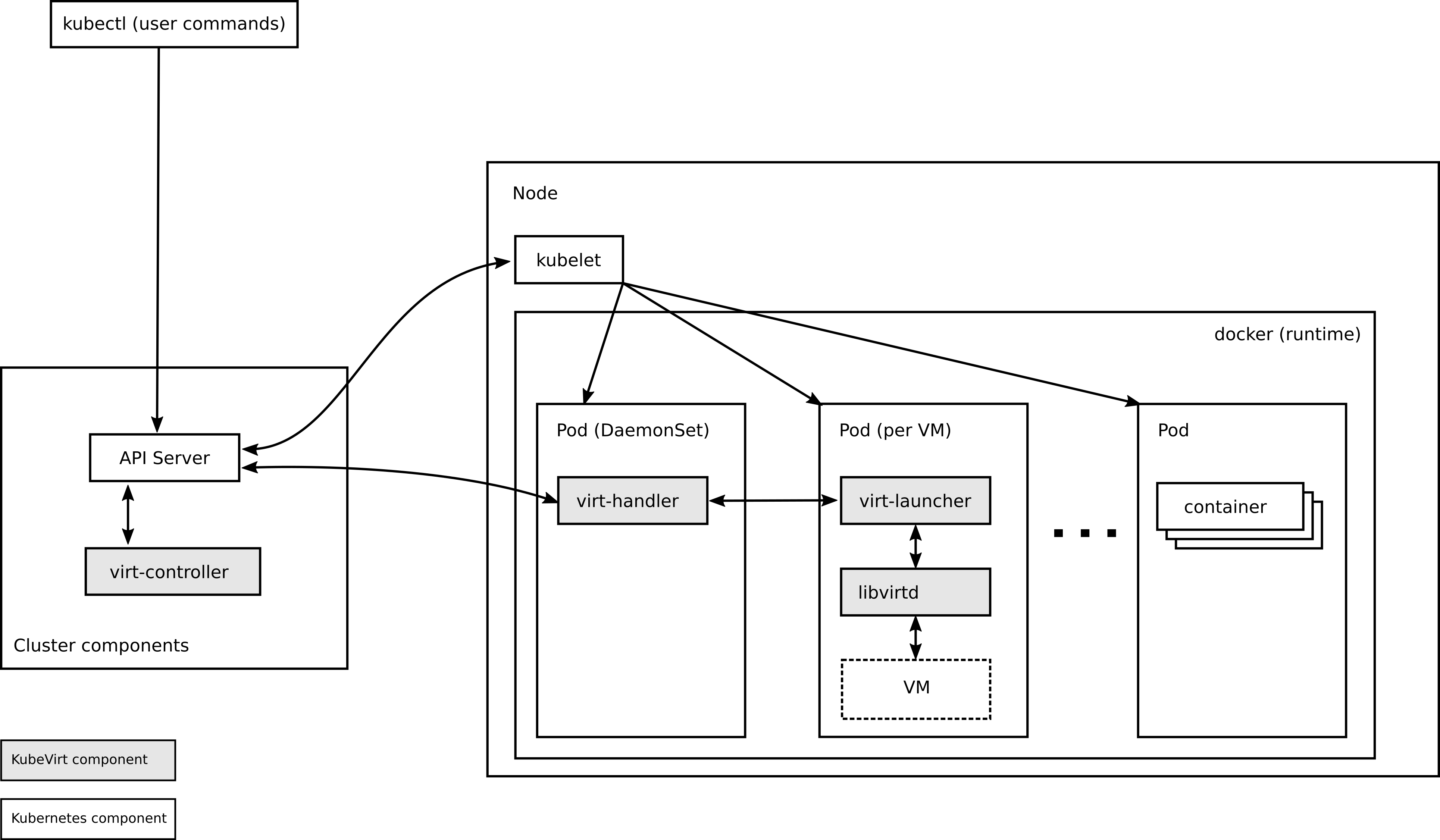
kubevirt架构
从kubevirt架构看如何创建虚拟机,Kubevirt架构如图所示,由4部分组件组成。从架构图看出kubevirt创建虚拟机的核心就是
创建了一个特殊的pod virt-launcher 其中的子进程包括libvirt和qemu。做过openstack nova项目的朋友应该比较
习惯于一台宿主机中运行一个libvirtd后台进程,kubevirt中采用每个pod中一个libvirt进程是去中心化的模式避免因为
libvirtd服务异常导致所有的虚拟机无法管理。
-
virt-api
kubevirt API服务,kubevirt是以CRD的方式工作的,virt-api提供了自定义的api请求处理,如
vncconsolestart vmstop vm等 -
virt-controller
- 与k8s api-server通讯监控
VMI资源创建删除等状态 - 根据
VMI定义创建virt-launcherpod,pod中将会运行虚拟机 - 监控pod状态,并随之更新
VMI状态 - 监控标记为”kubevirt.io/schedulable” node heartbeat
- 与k8s api-server通讯监控
-
virt-handler
- 运行在kubelet的node上定期更新heartbeat,并标记”kubevirt.io/schedulable”
- 监听在k8s apiserver当发现
VMI被标记得nodeName与自身node匹配时,负责虚拟机的生命周期管理
-
virt-launcher
- 以pod形式运行
- 根据
VMI定义生成虚拟机模板,通过libvirt API创建虚拟机 - 即每个虚拟机会对应对立的libvirtd
- 与libvirt通讯提供虚拟机生命周期管理
虚拟机创建流程
- client 发送创建VMI命令达到k8s API server.
- K8S API 创建VMI
- virt-controller监听到VMI创建时,根据VMI spec生成pod spec文件,创建pods
- k8s调度创建pods
- virt-controller监听到pods创建后,根据pods的调度node,更新VMI 的nodeName
- virt-handler监听到VMI nodeName与自身节点匹配后,与pod内的virt-launcher通信,virt-laucher创建虚拟机,并负责虚拟机生命周期管理
Client K8s API VMI CRD Virt Controller VMI Handler
-------------------------- ----------- ------- ----------------------- ----------
listen <----------- WATCH /virtualmachines
listen <----------------------------------- WATCH /virtualmachines
| |
POST /virtualmachines ---> validate | |
create ---> VMI ---> observe --------------> observe
| | v v
validate <--------- POST /pods defineVMI
create | | |
| | | |
schedPod ---------> observe |
| | v |
validate <--------- PUT /virtualmachines |
update ---> VMI ---------------------------> observe
| | | launchVMI
| | | |
: : : :
| | | |
DELETE /virtualmachines -> validate | | |
delete ----> * ---------------------------> observe
| | shutdownVMI
| | |
: : :
虚拟机存储
kubevirt目前提供了多种方式的虚拟机的磁盘
-
registryDisk 可定义image来创建作为虚拟机的root disk。 virt-controller会在pod定义中创建registryVolume的container,container中的entry服务负责 将
spec.volumes.registryDisk.image转化为qcow2格式,路径为pod根目录 -
cloudInitNoCloud
对虚拟机利用cloudinit做初始化,类似与nova中的configdrive,会根据
spec.volumes.cloudInitNoCloud创建包含iso文件,包含 meta-data 和 user-data。 -
emptyDisk
创建空的qcow2格式image挂载给虚拟机
-
PVC
上述几种disk都是非持久化的,随之pod的生命周期消亡,PVC是k8s提供的持久化存储。目前
kubevirt利用pvc挂载方式都是文件系统模式挂载, PVC首先被挂载在virt-laucherpod中, 且需要存在名称为/disk/*.img的文件,才挂载给虚拟机。 file模式虚拟化方式对虚拟机磁盘存储性能有很大的影响。熟悉openstack的朋友应该也了解nova-compute中如何使用ceph rbd image的,实质上是libvirt使用librbd以
network方式 将rbd image远程改在给虚拟机。而kubevirt中将POD ip移交给了虚拟机,那将意味着pod内的libvirt服务其实是无法直接使用networkdisk的。 要么增加网络代理转发即通过host来与网络设备通讯,要么就是采用k8s volumeMount:block feature来实现。kubevirt社区有PR已经实现了以Block的方式去使用是rbd image, 笔者手动merge并测试通过。 实质是使用了kernel rbd.ko,首先将rbd image map到host,block的mount方式 将不再以文件系统方式去挂载/dev/rbdx,而是为作为原始设备给pod,而pod内的libvirt就可以
block方式将rbd image作为 磁盘挂载给虚拟机。相较于PVC先格式化为文件系统并必须创建disk.img文件的使用方式,显然rbd image 以block device直接作为块设备给虚拟机少了本地文件系统层 单从存储效率讲都能提高不少。至于
librbd和rbd.ko的性能本文没有对比测试,有时间再补充。k8s
PVC后续版本应该也可以提供block mode方式的mount。 -
dataVolume
dataVolume是kubevirt下的一个子项目containerized-data-importer(CDI), 也是以CDR的方式增加
DataVolumeresource。 可以看成是从PVC和registryDisk衍生出来的,上面提过PVC使用是比较麻烦的,不仅需要PVC还需要创建disk.img, dataVolume其实将这个过程简化了,自动化的将disk.img创建在PVC中。 创建DataVolume是可以定义source即image/data来源可以是http或者s3的URL,CDI controller会将 自动将image转化并拷贝到PVC文件系统/disk/
虚拟机网络
kubevirt虚拟机网络使用的是pod网络也就是说,虚拟网络原生与pod之间是打通的。虚拟机具体的网络如图所示,
virt-launcher pod网络的网卡不再挂有pod ip,而是作为虚拟机的虚拟网卡的与外部网络通信的交接物理网卡。
那么虚拟机是如何拿到pod的ip的呢,virt-launcher实现了简单的单ip dhcp server,就是需要虚拟机中
启动dhclient,virt-launcher服务会分配给虚拟机。
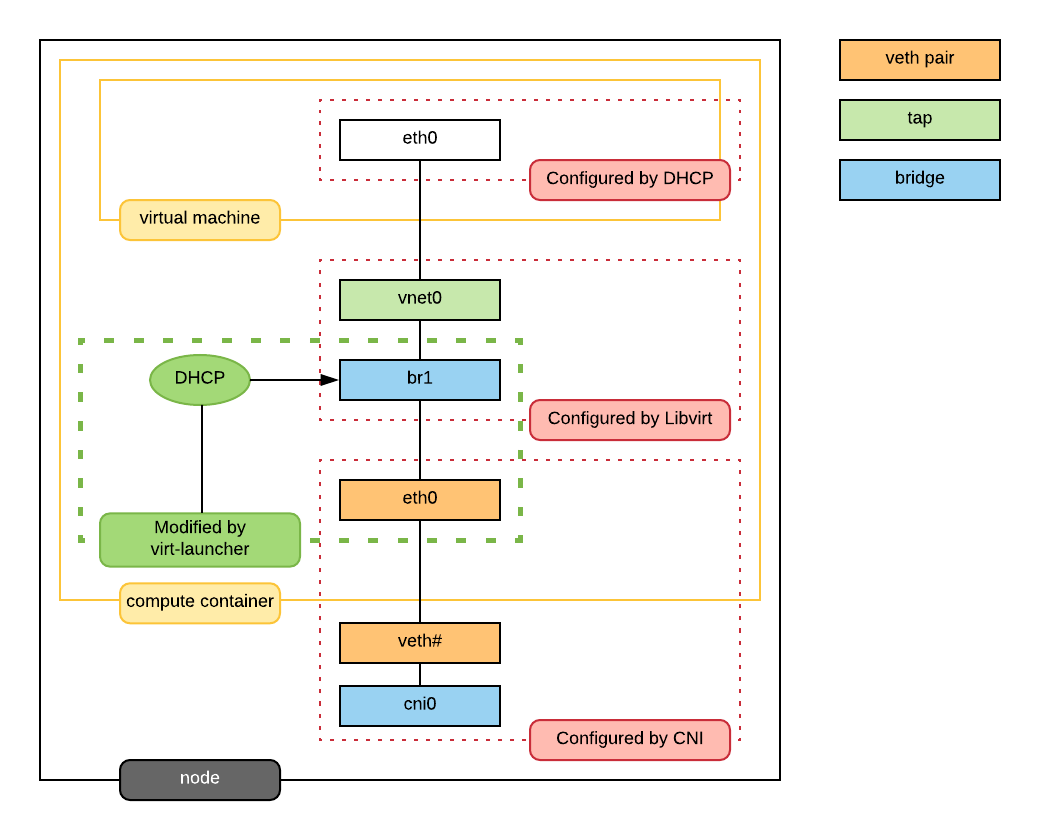
使用命令kubectl exec $virt-launch-pod -c compute -- brctl show可以看到bridge信息。
其中eth0就是pod与host网络通讯的veth peer网卡。也可以通过virsh dumpxml命令查看虚拟机的xml定义文件。
kubevirt部署
首先需要k8s环境,本文中使用的是v1.10.5版本,kubevirt选择v0.8.0,调用如下命令部署kubevirt
$ export VERSION=v0.8.0
$ kubectl create \
-f https://github.com/kubevirt/kubevirt/releases/download/$VERSION/kubevirt.yaml
kubevirt.yaml中定义了RBAC相关认证,默认管理服务都创建再kube-system namespace中,可以通过以下命令查看
资源,已经服务部署状态。当看到pods全部创建成功后,通过kubectl get vmis来检测服务是否可用。
kubectl get all -n kube-system -l kubevirt.io
NAME READY STATUS RESTARTS AGE
pod/virt-api-54cc86ff87-9xt8s 1/1 Running 0 14d
pod/virt-api-54cc86ff87-xvjg4 1/1 Running 0 14d
pod/virt-controller-769db5f6bf-2wgr4 1/1 Running 0 13d
pod/virt-controller-769db5f6bf-xwgks 1/1 Running 0 13d
pod/virt-handler-gpn6b 1/1 Running 0 2h
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/virt-api ClusterIP 172.30.7.81 <none> 443/TCP 16d
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
daemonset.apps/virt-handler 1 1 1 1 1 <none> 16d
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
deployment.apps/virt-api 2 2 2 2 16d
deployment.apps/virt-controller 2 2 2 2 16d
NAME DESIRED CURRENT READY AGE
replicaset.apps/virt-api-54cc86ff87 2 2 2 14d
replicaset.apps/virt-api-645f74c7fc 0 0 0 16d
replicaset.apps/virt-controller-658bf69f57 0 0 0 16d
replicaset.apps/virt-controller-769db5f6bf 2 2 2 14d
kubevirt on openshift
Kubevirt在openshift部署是类似的,唯一不同的是需要为kubevirt service account增加openshift权限 在需要使用block volumemount时,openshift需要修改origin-node的配置文件增加feature-gates “BlockVolume=true”
oc adm policy add-scc-to-user privileged system:serviceaccount:kube-system:kubevirt-privileged
oc adm policy add-scc-to-user privileged system:serviceaccount:kube-system:kubevirt-controller
oc adm policy add-scc-to-user privileged system:serviceaccount:kube-system:kubevirt-infra
oc adm policy add-scc-to-user privileged system:serviceaccount:kube-system:kubevirt-apiserver
创建虚拟机
准备虚拟机root disk
在kubevirt存储一节中介绍了kubevirt支持的存储类型,其中registryDisk和PVC方式可以为作为预装操作系统的虚拟机root disk。
registryDisk 方式
kubevirt提供了registryDisk的base docker image registry-disk-v1alpha
1 . 准备raw或者qcow2格式的虚拟机镜像,例如Windows---server-2012-datacenter-64bit-cn-syspreped---2018-01-15.qcow2
2 . 创建Dockerfile
FROM kubevirt/registry-disk-v1alpha
MAINTAINER "MinMin" <rmm0811@gmail.com>
# Add alpine image
COPY Windows---server-2012-datacenter-64bit-cn-syspreped---2018-01-15.qcow2 /disk/windows2012dc.img
3 . 创建image
docker build -t windows2012dc:latest ./
docker push windows2012dc:latest
4 . 更新vmi yaml文件中image
将vmi文件中的image更新为新创建的image
kind: VirtualMachineInstance
...
spec:
domain:
devices:
disks:
- disk:
bus: virtio
name: registrydisk
volumeName: registryvolume
...
- name: registryvolume
registryDisk:
image: windows2012dc:latest
PVC方式
PVC是k8s提供的持久化存储方式,当需要对虚拟机变更持久化存储时必须要采用这种方式。笔者在写本文时,kubevirt还未支持blockmode PVC,此章节
仅介绍file方式的。kubevirt中创建虚拟机是以pod空间中的/disk/目录下,那么意味着需要将PVC实现进行文件系统格式化,并创建disk/目录将
虚拟机root disk image拷贝至disk目录中。
这个过程可以手动完成比较繁杂,kubevirt提供了新的项目kubevirt/containerized-data-importer自动化这个过程,可参考示例
vm-alpine-datavolume.yaml)
通过DataVolume.spec.source定义虚拟操作系统的image路径。
创建vmi
自己创建vmi的yaml文件或者从github.com/kubevirt/kubevirt 项目中,cluster/examples下的
vmi-flavor-small.yaml
文件去创建虚拟机,创建完成后可以
使用ssh登陆查看虚拟机或者使用virtctl console 和 virtctl vnc来登陆虚拟机。
# kubectl create -f vmi-flavor-small.yaml
# kubectl get vmis
NAME AGE
vmi-flavor-small 15h
vmi_pvc-windows 14h
# kubectl get pods
virt-launcher-vmi-flavor-small-7m2cj 2/2 Running 0 2h
virt-launcher-vmi-pvc-windows-wvg5c 1/1 Running 0 14d